












ECONOMIC NEWS
Innovations and Warmth: The Journey of “Zolochе” Educational Space
Welcome to a world where education is transforming, adapting to the needs of modernity. In this...


ECONOMIC NEWS
Bezos Awards $100 Million to Eva Longoria and Admiral Bill McRaven for Societal Contributions
In a gesture of recognition for significant societal contributions, Amazon founder Jeff Bezos and his partner...


ECONOMIC NEWS
Glastonbury 2024 Line-Up Unveiled: Diversity, Female Empowerment, and Musical Legends Take Center Stage
The anticipation for Glastonbury 2024 has reached a fever pitch as organizers reveal a star-studded line-up...


ECONOMIC NEWS
Altria Group Sells $2.2 Billion Stake in AB InBev Amid Bud Light Sales Slump
Altria Group, the parent company of Marlboro cigarettes, has announced a significant move to sell a...


ECONOMIC NEWS
The 2024 Olivier Awards: A Celebration of Celebrity Talent and Theatrical Excellence
The stage is set for one of the most anticipated events in the British theatre calendar...


ECONOMIC NEWS
Reddit Reveals Pricing Strategy for Its Upcoming Public Offering
Reddit’s upcoming IPO is making waves in the financial world, with investors eagerly eyeing the social...


ECONOMIC NEWS
Saudi Aramco Boosts Dividends Amidst Profit Decline and Shifts Towards Renewable Investments
Saudi Aramco, the world’s largest oil company, has announced a significant increase in dividends despite a...


ECONOMIC NEWS
The Future of Maritime Transport: Robot Ships Set Sail
The concept of unmanned, remote-controlled ships may seem like a plot from a sci-fi movie, but...


ECONOMIC NEWS
Iconic ‘Sopranos’ Booth Sells for Whopping $82,600 on eBay
In a remarkable turn of events, the legendary booth from the final episode of “The Sopranos”...


ECONOMIC NEWS
Bitcoin Hits Record High Amidst Surging Mainstream Interest in Crypto
Bitcoin has soared to unprecedented heights, marking a remarkable turnaround after a prolonged period of uncertainty...


ART WORLD NEWS
Presentation of Business ML magazine in Dubai
On February 8, at the Pullman Dubai Downtown hotel on the Lolita Bar terrace (Dubai), Elvira...
MARKETING NEWS
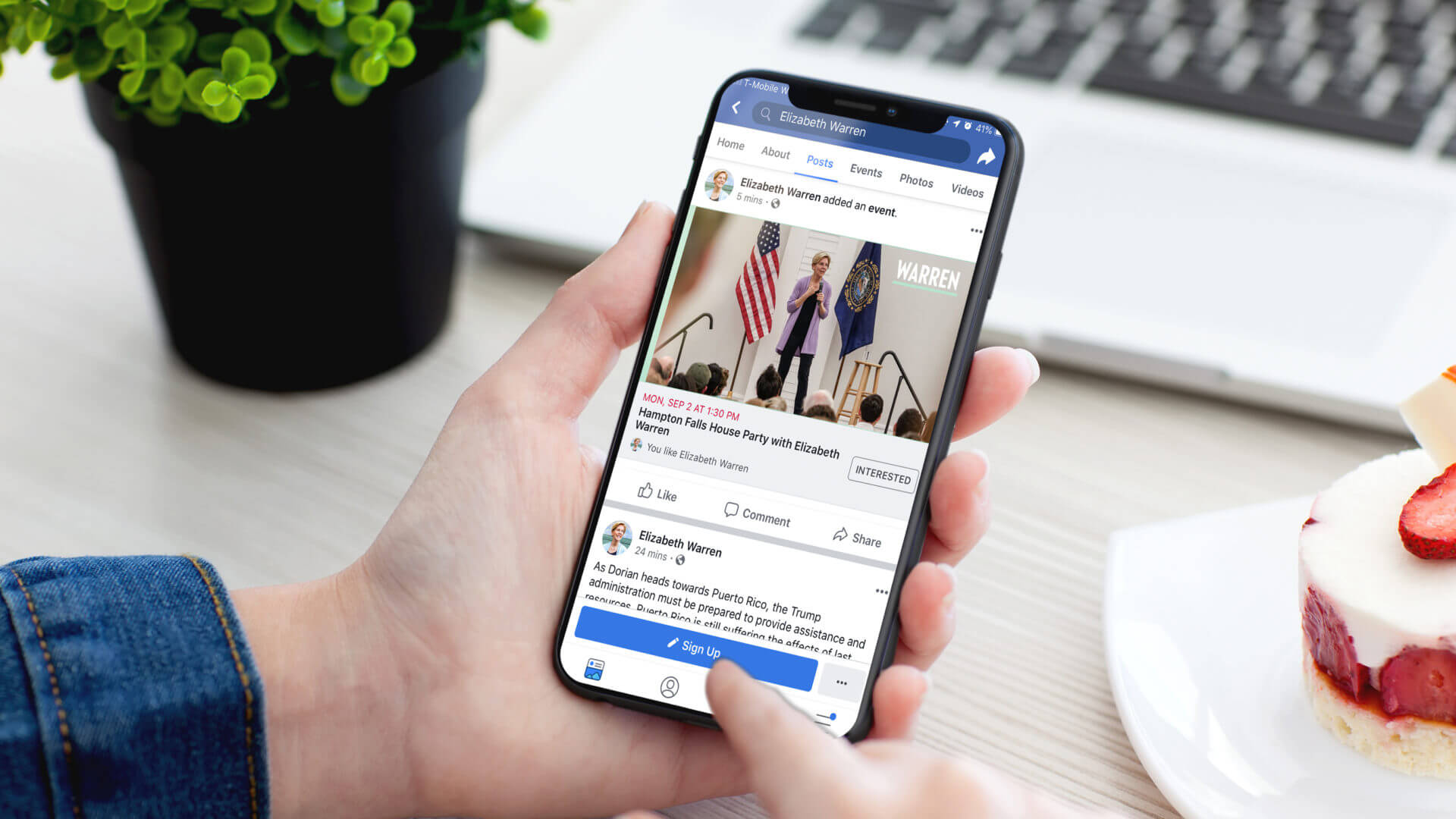
Facebook introduces new policies for political, social issue ads ahead of 2020 elections
[ad_1] Political advertisers on Facebook required to include EIN or FEC numbers. Facebook has updated its...
MARKETING NEWS
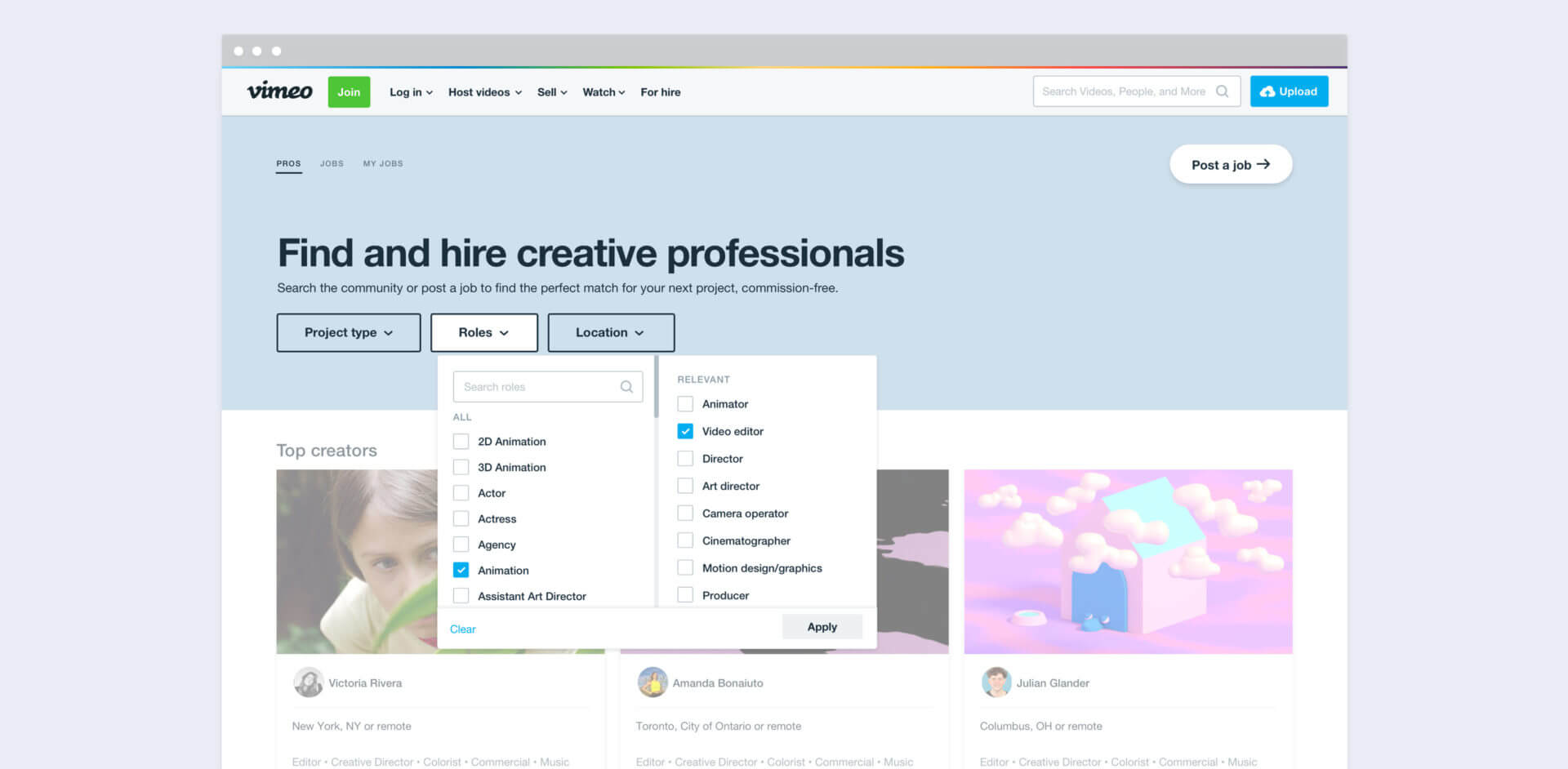
Vimeo’s ‘For Hire’ marketplace connects brands with qualified production talent
Vimeo has announced the launched a “For Hire” marketplace, a platform designed to connect brands with...

MARKETING NEWS
Elledgy: Elvira Gavrilova made a music video for the song of her own under the stage name
A famous Ukrainian producer, women’s fashion designer, and a popular Instagram blogger Elvira Gavrilova presented to...


ART WORLD NEWS
Stedelijk Museum Curator Dies – ARTnews.com
Rini Dippel, a Dutch museum official who spent much of her career at Amsterdam’s Stedelijk Museum,...

ART WORLD NEWS
Eriztina’s Life: the global social message in the new film by the production studio of the AC Amillidius
The international advertising company Amillidius has always paid special attention to the challenges facing society. The...

MARKETING NEWS
Prime Day sales topped Amazon’s Black Friday, Cyber Monday – combined
This year’s two-day Prime Day event has come to a close, and Amazon reported it was...


ECONOMIC NEWS
Republicans Pitch Biden on Smaller Aid Plan as Democrats Prepare to Act Alone
“He reiterated, however, that he will not slow down work on this urgent crisis response, and...


MARKETING NEWS
The Economy Is Improving Faster Than Expected, the U.S. Budget Office Says
The American economy will return to its pre-pandemic size by the middle of this year, even...


ART WORLD NEWS
HBO Documentary ‘Black Art’ Is a Moving Tribute to David C. Driskell – ARTnews.com
When art historian, curator, and artist David C. Driskell died last summer from complications related to...
Title



